- Digitalization
Categories:
In data engineering, we often treat heterogeneity as a hurdle: multiple formats, misaligned sources, disparate structures… But what if this diversity weren’t a problem to solve, but a resource to leverage? In complex systems, heterogeneity is not only inevitable—it’s essential for understanding and acting more intelligently on reality.
This article offers a different perspective: viewing data diversity as a competitive advantage. Through examples and design principles, we explore how well-managed heterogeneity can enhance decision-making and boost the adaptability of modern systems.
Data Diversity as a Reflection of the Real World
The world doesn’t produce homogeneous data. A building doesn’t “speak” the same way as a temperature sensor, a weather API, or a human operator. Each source has its own language, frequency, and granularity. This diversity isn’t a design flaw—it’s a direct reflection of environmental complexity.
When we try to force a single structure onto all data, we risk oversimplifying and losing valuable information. In contrast, recognizing and managing this diversity allows us to build richer, more accurate, and more resilient insights—especially in dynamic or uncertain environments.
Heterogeneity as Strategy: Three Core Principles
- Separate to Understand:
Decoupling data sources into independent services allows each stream to be handled according to its nature, without imposing artificial adaptations. This principle of encapsulation is key to scalability and maintainability: it lets systems grow as needed and makes it easier to pinpoint bottlenecks or errors without collapsing the entire architecture. - Unify Without Erasing Identity:
Transforming data into common models doesn’t mean stripping away its essence. Using standardized—but traceable—intermediate representations enables comparisons, validations, and cross-referencing across disparate sources, without diluting their original meaning. The secret is in translating, not erasing the accent. - The Right Data in the Right Place:
Not all data should be stored the same way. Time series, relational entities, and unstructured objects each have different requirements. Respecting these differences optimizes both performance and system clarity. Designing storage models intentionally—based on data nature—preserves informational value and simplifies future use.
Practical Applications: Diversity as Operational Strength
In real-world projects, integrating diverse sources is not an exception—it’s the norm. Some typical examples include:
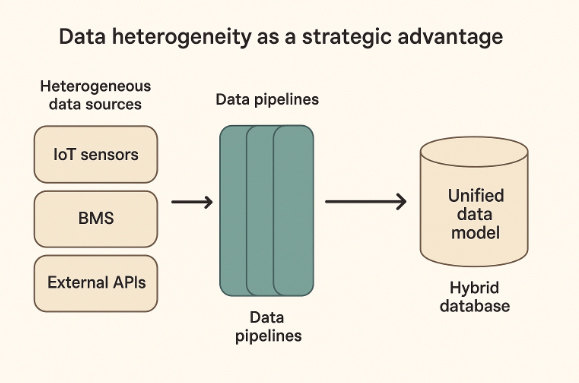
- IoT Sensors: Capture real-time parameters such as temperature, humidity, CO₂, or flow, sending periodic pulses from the physical environment. They’re easy to install and scale.
- BMS (Building Management Systems): Provide internal operational data such as modes of operation, damper states, or technical setpoints—crucial for building energy efficiency.
- External APIs: Allow for integration of contextual data—weather, energy consumption, pricing, etc.—on demand or continuously.
- Prediction and Optimization Models: Generate derived data from historical and real-time analysis, helping to build more effective or automated strategies.
This diversity isn’t forcibly homogenized—it’s orchestrated: data pipelines that respect the origin, channel flows through defined rules, and converge into a hybrid model—validated, flexible, and traceable—capable of supporting informed and agile decisions.
The Real Value of Listening to Every Language
Instead of fighting diversity, we can build systems that listen to it, understand it, and make use of it. A wealth of perspectives—languages, sources, formats—leads to decisions that are more accurate, adaptive, and sustainable. The goal isn’t to standardize all data, but to coordinate it intelligently and with contextual awareness.
Designing with this mindset not only solves technical challenges—it opens up new business opportunities and paths for technological evolution. Properly understood, heterogeneity stops being a burden and becomes a driver of value.

Rolando Mandefro
Rolando Mandefro es ingeniero de datos con experiencia en bases de datos relacionales y procesamiento de datos. Posee una Maestría en Ingeniería de Sistemas Electrónicos por la Universidad Politécnica de Madrid (UPM) y una Licenciatura en Ingeniería Automática por la Universidad Tecnológica de La Habana. Actualmente, trabaja en Sener como ingeniero de datos, donde contribuye en la automatización y optimización de procesos ETL para la integración y transformación de datos en RESPIRA, una solución de inteligencia artificial diseñada para mejorar la eficiencia energética, el confort térmico y la calidad del aire en entornos industriales y comerciales. Su trabajo se centra en el procesamiento y modelado de datos para la gestión y análisis de grandes volúmenes de información.